
Hey, tea lovers! Today I will show you how to specifically select the desired folders or files in Flink Batch Job programmatically. We will discuss when given a root path you can decide which file or folder to read in Flink Batch Job.
And why suddenly do I pick up this topic you say? Well, I was working on such a task myself where I needed to read the S3 files which are under folders with dates. Those date folders are in a rolling fashion like , 2021_01_13_1, 2021_01_13_2, 2021_01_13_3 and so on. And in these folders, there were multiple files, so based on the given date I needed to read all those files which are in the given date folder (the folder name should contain the date obviously).
There may be other ways of doing it, but I couldn’t find any of them. So I had to create it on my own. If there is any other better way to do it, please let me know, it will not only help me but countless other programmers as well.
So let’s get started. But before preparing your cup of tea sip and code.
Update
I have written a new post on the Batch code with the streaming mediation. Please do check out the How to Run Flink Batch as Streaming.
Prerequisites for this Code
First thing, you should know at least the basics of Flink. The code I am showing is from Flink 1.7, but I suppose it should work for other versions as well. If not please let me know in the comments.
For the Installation of Apache Flink on Mac OS check out the post “ How to Install Apache Flink On Mac OS“.
And for theWindows check out the post “ How to Install Apache Flink On Local Windows“
Have Ubuntu? Then refer to " How to Install Apache Flink On Ubuntu".
Knowing Java version 8 or above is a huge plus, as I will be using the Stream API to make the code more readable and efficient. If you are not familiar with Stream API, you can check my post on it: " Stream API: The Hero Without a Cape". Also for simplicity, I will be using the local file and not S3.
Create a New Flink Project
The best way to create a Flink project is to use Maven Archetype. As I stated I will be using Flink 1.7, so here is the command to generate it via mvn. You can change the version to your need.
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.7.1
You can also use this command instead.
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.7.1
This will ask you for the group, artifact ids, and other details. Once you are done, go to pom.xml. There you will see the Flink dependencies scope as provided. You may need to remove that scope if you are planning to run it locally. However, you can run it locally with some modifications to your project in your IDE. but that’s a different topic altogether, so you can look for it on the internet.
The easiest and the best solution is, I have created the project repo on GitHub, pull it, and start using it.
Setup Specific Folders for Flink Job
Now that we have our project, let’s quickly set up the input environment. For this demo, I will be creating the folders which have the dates in YYYY_MM_DD format and have the numbers appended to them at the end. For example, 2021_01_01_01, 2021_01_01_02, 2021_01_02_01 and so on. In these folders, we will be having files with random numbers, which we will simply sum numbers.
This is what my Input data File structure looks like.
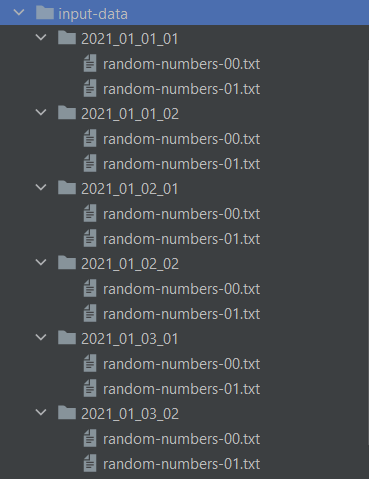
Flink Specific Folder input strucure
And the data is in the following format:
75
3
117
129
304
6
676
299
787
843
I have put the input-data folders inside the resource directory. You can copy it and put wherever you like. I will be putting it in D:\projects\temp\flink-specific the folder.
Program to Read Specific Folders in Flink
Now that we have set up our environment, let’s jump into the code. As I said, my path will be the D:\projects\temp\flink-specific\.
Take Input for the Flink-Specific Folders Program
As you must know we can parse the command line argument with the ParameterTool class. I will be using that to get the inputs. For the demo, I passed the default values in the program.
ParameterTool param = ParameterTool.fromArgs(args);
// get the inputFolder path from arguments otherwise pass the default path
String inputFolder = param.get("inputFolder", INPUT_FOLDER);
log.info("The input folder path is {}", inputFolder);
String date = param.get("date", "2021_01_01");
Select Specific Folders in Flink
We will be using Path class of Flink lib. First, we will pass the root folder path to it and get a list of all its subdirectories of it. Next, we will filter out the folders by checking if they contain the date Then collect all the folders with it.
The information of the folder will be fetched by the getFileSystem() method, which returns the FileSystem object. Now, to get all the subdirectories or folders, we need to call the method listStatus(path), the path is the same path we created earlier.
Path inputFolderPath = new Path(inputFolder);
FileSystem fileSystem = inputFolderPath.getFileSystem();
FileStatus[] fileStatuses = fileSystem.listStatus(inputFolderPath);
Select Specific folders: For Loop
Now that we have all the files and folders within let’s filter out our specific folders which contain the Date. This code is with the normal For Loop on the fileStatuses.
List<Path> foldersWithGivenDate = new ArrayList<>();
for (FileStatus fileStatus : fileStatuses) {
// it should be a directory
if(fileStatus.isDir()){
// get the path of the folder
Path folderWithGivenDate = fileStatus.getPath();
//check if the directory name contains the date
if (folderWithGivenDate.getName().contains(date)) {
//add it to the list
foldersWithGivenDate.add(folderWithGivenDate);
}
}
}
Select Specific folders: Stream API
Now, the same thing using Stream API is shown below. This makes it more clear and readable. Also, the Stream API code is much less redundant.
// the same thing using Stream API
List<Path> foldersWithGivenDateWithStreamApi = Stream.of(fileStatuses)
.filter(FileStatus::isDir)
.map(FileStatus::getPath)
.filter(path -> path.getName().contains(date))
.collect(Collectors.toList());
Both are the same, but which one do you prefer? Please let me know in the comments.
Create DataSet from multiple Paths in Flink
We got all the paths, the locations, of the file we needed. One thing to notice is that I am using folders or directories here as input. As I need to read all the files within the folder. But in case you need to filter based on the files, you can then play with the FileStatus object. Think of this object as a File object in Java.
Ok, back to the folders. For the Flink Batch, I will be using the createInput method of the ExecutionEnvironment. It takes an TextInputFormat object. In this TextInputFormat I will be putting the paths we generated. Here is how to do it.
// convert list to array
Path[] foldersWithGivenDateArr = foldersWithGivenDate.toArray(new Path[0]);
TextInputFormat textInputFormat = new TextInputFormat(null);
textInputFormat.setNestedFileEnumeration(true);
// pass the arr to the text input
textInputFormat.setFilePaths(foldersWithGivenDateArr);
The Flink Batch Job with Specific Folder Data
Up until now, we were just setting up the input we needed for the program. The main Flink execution starts now. We will be using them ExecutionEnvironment as opposed to StreamExecutionEnvironment the Batch job, the bounded data input. First, we will create a DataSet user createinput and will pass the created TextInputFormat object. Next, we will parse the input to Integer. Then, sum all the numbers using reduce and collect them.
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
List<Integer> result = env.createInput(textInputFormat)
//convert string to integer
.map(Integer::valueOf)
// sum the numbers
.reduce(Integer::sum)
.collect();
// will only have one element though
log.info("The sum of all the data is {}", result);
Conclusion
That is it for this post. In this post, we mainly talked about how to list and filter the files of the given folder in Flink. Then select the specific one and create an input from them via TextInputFormat. Using this we can simply create a Dataset with desired input files.
The whole code can be found on GitHub. I hope this will help you. I will be creating multiple posts on the same topic. The next post will be on the Integration test on the Flink. I will update you about the latest post on our social media platform. You can follow us on @coderstea on Twitter, Instagram, Linked In, and Facebook.
See you in the next post. HAKUNA MATATA!!!