Hey! tea lovers! In this post, we will be discussing how HashMap, the key-value-based data structure, works in Java. And it is one of the most asked interview questions as well. It is the core feature we as a developer use daily. Primarily used for easy and faster access to data based on the key. So let us see how it stores, retrieves and updates the data.
I will put more articles under the Simply Explained tag. For now, let us get started with HashMap. So make your cup of tea to sip and code.
Before HashMap, What is a Map
The Map is a key-value-based data structure, where we store values with a specific key. This key is what we later use to retrieve that value. Every key is unique. If you put the same key with a different value then it will be overridden.
In Java, we use Map<K, V> for the same purpose. However, it is an interface and we have to use the implementation. There are various implementations such as HashMap, LinkedHashMap, and TreeMap. One thing to note is that Technically, Map is not a part of the true collection framework as it does not implement a Collection interface.
To get started with how HashMap works, we have to take a look at hashCode() & equals() in Java.
equals()
The equals() method of the Object class, is used for checking whether or not the current object equals or is the same as the object being passed. By default, it checks the object’s memory address of the instances. If both objects have the same memory address then they are equal.
public boolean equals(Object anotherObj)
hashCode()
The hashCode(), from the Object class, is used in a way to identify an object with an integer. By default, it returns the object’s memory address in an integer format. The same object must return the same hashcode everytime its called.
public int hashCode()
The Bonding of equals() & hashCode()
Now that you know how equals() and hashCode() functions work, let us see why they are important and what the bonding is between them.
The rule is, If equals returns true, the hashcode of the comparing object must be the same.
For wrapper classes, Integer, Float, etc, or String, you don’t have to worry about them. But for your custom classes, you might want to override them but for special cases and not all the time. For example, if you are planning to use it as a key in Map or you don’t want any duplicate objects and that duplication is based on some id fields of the class.
When overriding it, make sure that equals() is based on the hashCode() and hashCode() is based on unique value. So, if it obj1.equals(obj2) is true then obj1.hashCode() == obj2.hashCode() must be true. If not they can behave very weirdly.
Suppose I have a int id in my class which must be unique for each object and I don’t care if any other fields are duplicated except this. And I want to make this object a key for a Map. So I will return it from my hashcode and in equals() we will use this id.
@Override
public int hashCode(){
return this.id;
}
@Override
public int equals(Object obj){
if(obj == null) return false;
if(! obj instanceOf ThisClassName) return false;
//You can have more conditions with different fields.
// I am just taking a simple one for simplicity
return this.id == obj.id;
}
Bucket in HashMap
A Bucket is nothing but an array of nodes. Each node is a LinkedList type of data structure. Multiple nodes can reside in the same bucket. The bucket number is the index or position of a bucket. Simply put, each bucket contains a linked list.
How HashMap Works
Now that we have looked at all the pieces, now let’s put them together. Here it goes.
Inserting a Key-Value Pair
When we initialize a HashMap, the Buckets or array are initialized. Calling put(key, value) to insert the content following things happens.
- It generates the hash of the key object with the inbuilt hash function to determine the index number or the bucket. It generally looks like this.
- index = keyObject.hashCode() & (numberOfBuckets -1)
- The index is what the bucket is. Here we have used hashCode().
- If the index or bucket is empty, we add the key, value from put, into the LinkedList of that bucket as Entry<K, V>.
- Now, if the bucket is not empty, then we traverse or loop through the LinkedList of that bucket. This is called a hash collision.
- For each keyObject in the list, we call its equals(newKeyObject).
- If it returns true, then this Entry<K, V> will be replaced by the new Entry.
- If it reached the end of the list, it gets added there i.e the new Entry<K, V> is get added at the end of the LinkedList for that bucket.
- And the procedure gets repeated for each put method.
You can see it in the image below.
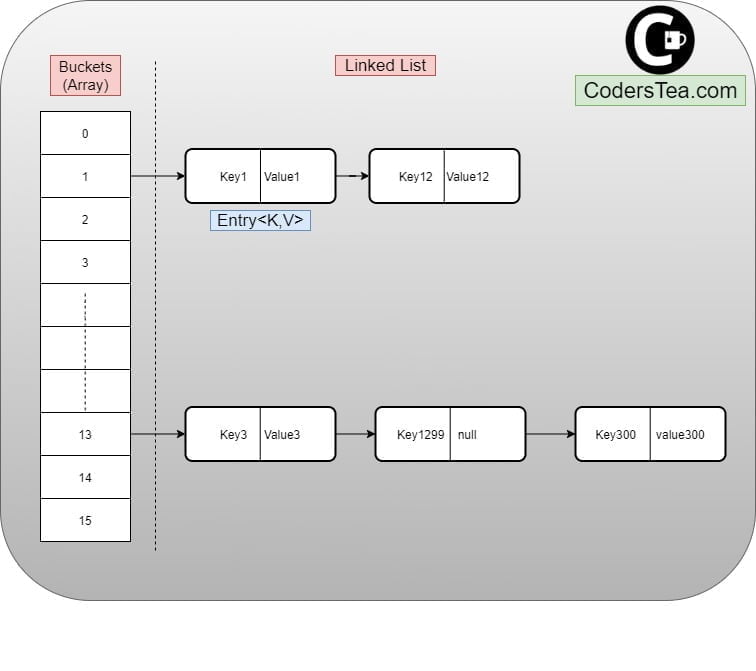
Hash Map Basic Structure
Retrieve the Value
HashMap is known for O(1) time complexity for retrieving the data, however, that is not entirely true. The O(1) is for the average-case scenario, not the worst case. It all depends on the hash function being used. If it is bad and gives the same bucket for each key, then you are having the time complexity of a LinkedList. That’s why it is very important to write a better hashCode and equals method implementation. If possible, always use wrapper classes for the keys. It is much more efficient and you don’t need to worry about poor implementation.
Ok, back to retrieve the value. You just have to call get(key), and it will return the value associated with that key. The process is similar to putting except for replacing or adding.
- Determine the bucket from hashCode() using the hash function we used in put() method.
- If empty returns null.
- Else, it loops through the list of that bucket.
- For each Entry <K, V> in the list, it calls the equals() method. If equals() returns true, then it returns this Entry’s value.
- If no key is matched then returns null.
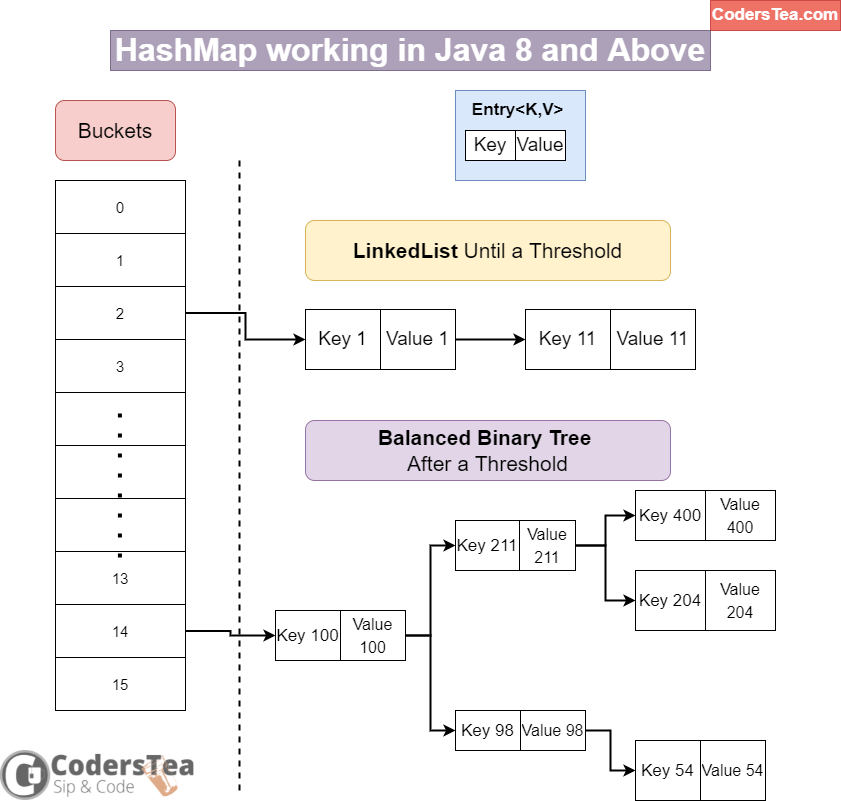
Update in HashMap Working from Java 8
Since Java 8 there is been a slight change in the working of HashMap. Do you know what it is? It’s a Binary Tree. Yes, It uses a Binray Tree instead of a LinkedList. But not right off the bat. When the map size reaches a certain threshold, it replaces the LinkedList with the Binary Tree. And that too a Balanced Binary Tree. This improves the worst time in a collision from O(n) to O(log n).
In nutshell, if the key is smaller than the current key, it goes to the left subtree, otherwise the right subtree. And it continues until it reaches the end, and put the new Entry there. And for get the operation, it traverses similarly until it reaches the desired key or the end of the tree.
Conclusion
That’s it for this post. We looked at what is HashMap, the different components used in HashMap work, and how all the pieces fit together to make this happen. I would say, it was a simplified version of how it works.
You can learn more about other Java features such as Stream API, Best Practices, and Functional Programming. Please go to GitHub for the code.
See you in the next post. HAKUNA MATATA!!!